
Cómo no estar en Google
Vía @kontsultaMU, Josu, responsable de una tienda online, nos pregunta cómo impedir que Google almacene o indexe una sección de su sitio web. Es una sección, que tiene que estar pública (la utiliza para comunicarse con sus proveedores), pero no quiere que sea indexada por Googlebot (Araña de Google) ya que no quiere que las páginas que componen dicha sección aparezcan en los resultados de búsqueda (SERP) de Google.
Esta suele ser una pregunta bastante habitual en los cursos de SEO. «¿Cómo puedo prohibir que Google guarde mis páginas web?» Vamos a tratar de dar respuesta a esa pregunta.
Siempre tenemos páginas (Aviso Legal, Privacidad, Páginas Vacías de Contenidos, Formularios, páginas obsoletas, etc.), Directorios (intranets, Secciones duplicadas, carpetas o secciones que queremos mantener públicos pero no indexables, etc.) o Sitios Web Completos (Por ejemplo, cuando estamos a nivel de prototipado y queremos que el Cliente vea el aspecto que va tomando el sitio web, pero al no estar completa no queremos que Googlebot indexe la información.
La solución está en robots.txt Robots.txt se puede utilizar tanto cómo una etiqueta META (en el HEAD) cómo un fichero de texto llamado así que colgaremos en la raíz del servidor web y que por tanto Googlebot (o los robots de Yahoo, Bing, u otros buscadores) procesará de primera mano. Opciones:
- Bloquear una página concreta. Lo mejor es utilizar Etiqueta META. Ideal cuándo solo queremos dejar fuera una página concreta (por ejemplo, la del aviso legal). Con poner en el <HEAD> la siguiente línea, será suficiente <META NAME=»ROBOTS» CONTENT=»NOINDEX, FOLLOW»> Cuando además queremos que no indexe las URLs que cuelguen de esa página podemos poner el «noindex.nofollow» para que el robot no siga los enlaces que contiene esa página (por ejemplo, cuando queremos bloquear secciones concretas). También se puede poner una línea en el fichero robots.txt Por ejemplo: Disallow /aviso-legal.html Para concretar el robot de Google pondremos User-Agent: Googlebot Si queremos que funcione para todos los robots de todos los buscadores pondremos User-Agent: *
- Bloquear una sección concreta. Para ello lo mejor es utilizar el fichero de robots.txt que colgará de la raíz. Si queremos que no indexe una sección concreta llamada Intranet pondremos en el fichero robots.txt la siguiente entrada Disallow /Intranet/
- Bloquear todo el sitio web. Lo podemos hacer poniendo la etiqueta META <META NAME=»ROBOTS» CONTENT=»NOINDEX, NOFOLLOW»> en la página principal. O en el fichero robots.txt Disallow / Es la solución habitual que suelen hacer los CMS (WordPress o Joomla) cuándo los configuramos para que no sean accesibles por los buscadores.
Como curiosidad pongo 2 pantallazos de ejemplos de fichero robots.txt
El de la SGAE (donde se ve que trata de evitar aparecer posicionado para el término ladrones)
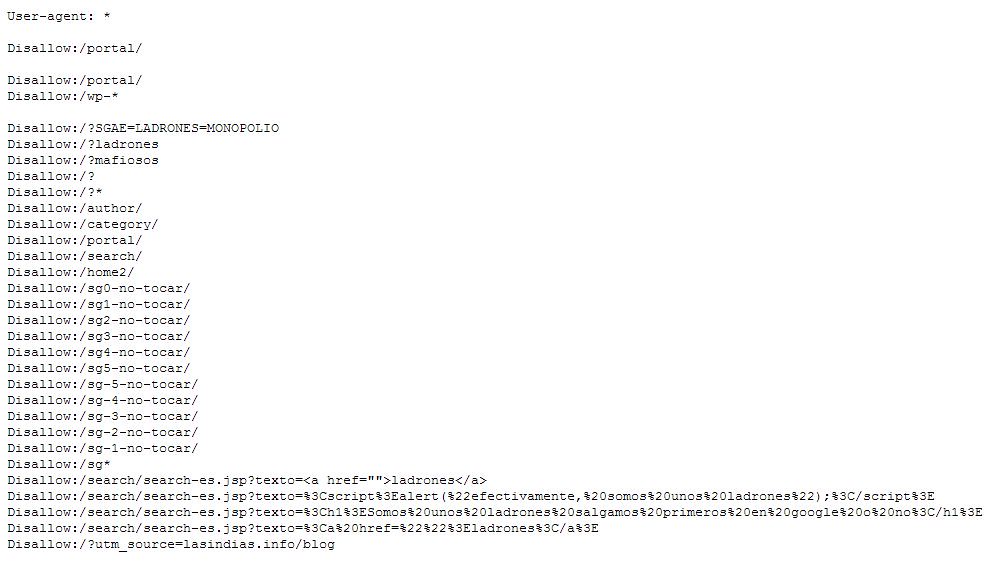
Y el del BOE, dónde se pueden ver las URLs de los boletines obsoletos que no quieren ser visualizados:
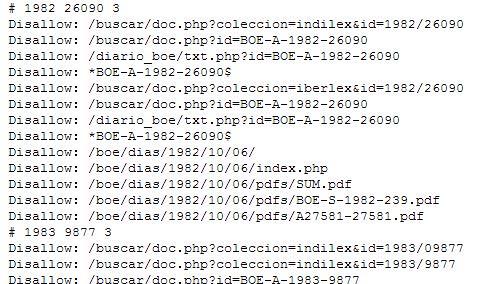
Con todas estas opciones conseguiremos impedir que el robot de los buscadores entre en ciertas (o todas) zonas de una web. En los casos en los que el robot ya haya pasado y por tanto esa información ya esté indexada, además de adoptar alguna de las soluciones vistas deberemos eliminar la URL de la Base de Datos del buscador. En el caso de Google lo haremos a través de Herramientas para Webmaster Tools.
Hola buenas, me gustaría diferenciar dos cosas:
1 – robots.txt dice donde puede un robot entrar o no, pero no dice que se indexe o no, si por ejemplo pones Disallow:/ a un sitio este seguirá apareciendo pero en el snnipet pondrá que el robot no ha podido acceder al contenido.
3 – La meta etiqueta robots, dice que un contenido no se debe indexar, pero no dice nada de que el robot acceda o no, de hecho un recurso SEO muy usado para contenidos duplicados es noindex,follow.
De todas forma la mejor manea de eliminar una url de Google es solicitando su eliminación en WMT y posteriormente impidiendo el nuevo acceso con robot.txt tal como Google lo explica en su documentación
Otro caso divertido es la eliminación de Urdangarin
en la web de la casa real con el robots.txt. http://www.casareal.es/robots.txt
Gracias por el aporte!! un pequeño descuido en el robots.txt puede hacer que Google te desindexe la web